What are these models that have revolutionized natural language processing? A powerful class of neural networks is transforming how we understand and interact with language.
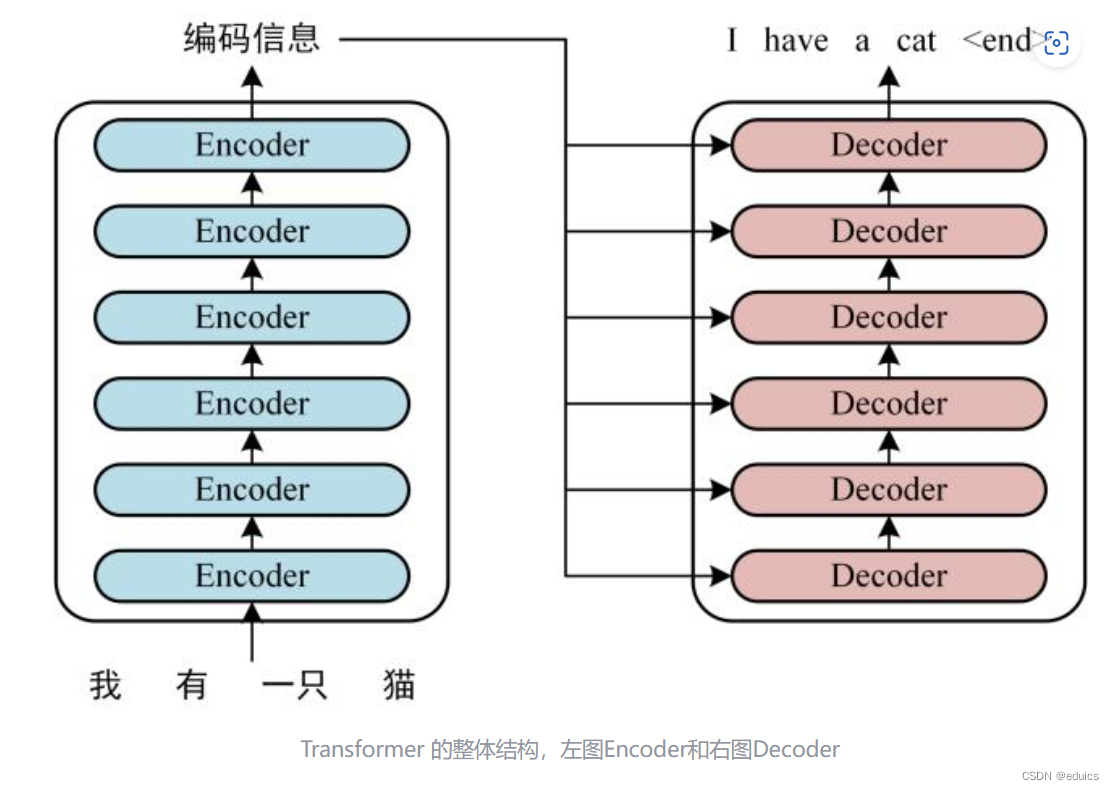
These models, often referred to as transformer networks, represent a significant advancement in artificial intelligence, particularly in natural language processing tasks. They are characterized by their ability to capture intricate relationships between words in a given text. Instead of processing words sequentially, like traditional language models, transformers analyze all words simultaneously, enabling them to grasp context and meaning with greater accuracy and nuance. For instance, a transformer model can readily understand the meaning of a sentence even when the words are reordered, a task challenging for prior methods. These models have become fundamental to applications such as machine translation, text summarization, and question answering.
The key benefits of these models lie in their superior performance and adaptability. Their ability to understand complex sentence structures and subtle nuances leads to more accurate and insightful results in various applications. This is particularly important in tasks requiring a deep understanding of language. Furthermore, the model's architecture, based on self-attention mechanisms, allows for scalability and the processing of longer sequences of text than earlier methods. This allows these models to handle more complex and nuanced language tasks, driving improvements in areas like sentiment analysis, text generation, and even code generation. Their historical context is rooted in the desire for more sophisticated and effective language models, pushing past limitations of sequential processing and enabling a more holistic understanding of context.
Transformer Models
Transformer models represent a significant advancement in natural language processing. Their core principles underpin numerous applications, demonstrating a profound impact on understanding and processing language.
- Contextual Understanding
- Attention Mechanisms
- Sequential Processing
- Multi-tasking Capabilities
- Scalability & Efficiency
- Deep Learning
These models excel at capturing intricate relationships between words, achieving contextual understanding far surpassing previous methods. Attention mechanisms allow them to focus on relevant parts of the input, enabling precise language analysis. While not entirely abandoning sequential processing, these models process multiple words concurrently. Their remarkable ability to handle various language tasks simultaneously highlights their adaptability. Scalability and efficiency further enhance their utility. The deep learning foundation allows for complex interactions and insights. For example, their proficiency in machine translation goes beyond literal word-for-word conversions, focusing on intended meaning and context.
1. Contextual Understanding
Contextual understanding is a crucial aspect of advanced language models, and transformer models are particularly adept at achieving it. This capability arises from the unique architecture of transformer models, which enables a nuanced grasp of the relationships between words in a sentence, going beyond a simple sequence-to-sequence translation. The significance of contextual understanding lies in its ability to accurately interpret meaning, particularly in complex or ambiguous sentences.
- Word Sense Disambiguation
Transformer models leverage the context surrounding a word to determine its specific meaning. For instance, the word "bank" can refer to a financial institution or the edge of a river. Contextual understanding allows the model to accurately choose the correct meaning based on surrounding words. This ability is crucial for tasks like accurate text summarization and machine translation.
- Sentence Structure and Relationships
Transformer models analyze the syntactic and semantic relationships within a sentence to infer the overall meaning. Understanding the nuances of sentence structure, such as passive voice or complex clauses, enables the model to interpret the relationship between different parts of the sentence accurately. This is essential for tasks such as complex question answering and text generation that requires comprehension of grammatical structure.
- Implied Meaning and Pragmatics
Beyond literal meanings, transformer models can discern implied meaning and contextual cues. For instance, understanding sarcasm or humor requires going beyond the explicit words used. Models with strong contextual understanding can capture this nuance, enabling more sophisticated applications, such as detecting sentiment or generating creative text.
- Handling Ambiguity and Variation
Language is inherently ambiguous. Transformer models can address this ambiguity by considering the context in which words and phrases appear. They can also cope with variations in language, style, and dialect, by understanding the overall contextual situation. This flexibility is important for handling diverse text data and maintaining accuracy across different language styles.
In summary, contextual understanding is a core strength of transformer models. By analyzing the intricate relationships between words and sentences, these models can achieve a deeper, more accurate understanding of meaning. This ability underpins their success in various language processing tasks, enabling applications like summarization, translation, and question answering to function effectively in the context of natural language complexity.
2. Attention Mechanisms
Attention mechanisms are a fundamental component of transformer models. Their role in these models is crucial, enabling a significant leap forward in natural language processing tasks. These mechanisms allow the model to focus on the most relevant parts of the input data when processing it, which is particularly vital for understanding context and relationships between words in a sentence or document.
- Selective Focus on Information
Attention mechanisms act like a spotlight, directing the model's attention to specific parts of the input sequence that are most relevant to the current task. Imagine reading a long article; attention lets the model focus on the key phrases or sentences directly related to the question being asked, rather than getting bogged down in unnecessary details. This selective focus ensures that the model prioritizes crucial information while disregarding less pertinent parts of the input. This is a marked improvement over traditional recurrent models that process information sequentially, potentially overlooking crucial contextual clues.
- Contextual Understanding through Relationships
Crucially, attention mechanisms capture relationships between different parts of the input. In a sentence, a word's meaning often depends on its relationship to other words. Attention allows the model to establish these relationships, recognizing how different parts of the sentence interact to create meaning. For example, in understanding the meaning of the pronoun "it," the model leverages attention to find the noun or phrase to which "it" refers.
- Dynamic Weighting of Input Elements
Attention mechanisms dynamically assign weights to different parts of the input. Words or phrases deemed more important receive higher weights, while those less crucial are assigned lower weights. This dynamic weighting ensures that the model prioritizes elements that hold greater significance in understanding the overall input. This contrasts with fixed weighting schemes used in earlier models.
- Improved Performance on Complex Tasks
Transformer models with attention mechanisms demonstrably outperform previous models on tasks demanding complex contextual understanding, like machine translation, text summarization, and question answering. This improved performance stems directly from the capacity of attention mechanisms to discern the intricate interplay of words and phrases within the input text, a feat not easily replicated in sequential models. The efficiency and effectiveness of the attention mechanism is crucial for handling large and complex inputs in natural language processing tasks.
In essence, attention mechanisms in transformer models facilitate a more nuanced and context-aware understanding of language. By selectively focusing on relevant input elements, these models gain a deeper comprehension of the intricate relationships within the data. This ability is pivotal to the exceptional performance of transformer models across a broad spectrum of natural language processing applications.
3. Sequential Processing
Sequential processing, a cornerstone of traditional language models, involves processing input datalike textone element at a time, following a linear order. This approach, while foundational, presents limitations in capturing the complex interplay of information within longer sequences and nuanced relationships between words. Transformer models, in contrast, often employ parallel processing to overcome these limitations, fundamentally altering how language is understood and processed.
- Limitations in Contextual Understanding
Sequential models struggle with capturing the full context of a word or phrase. Consider a sentence where the meaning of a word is heavily influenced by words preceding it. A purely sequential approach might only access immediate preceding elements, missing the broader context necessary for accurate interpretation. This limitation is especially apparent in long documents where context spanning multiple sentences is required for comprehensive understanding.
- Computational Efficiency Bottlenecks
The sequential nature of processing can lead to computational inefficiencies, especially with longer sequences of data. Each element needs to be processed one after another, which can significantly impact processing time and overall performance, particularly for large datasets or complex tasks. This contrasts sharply with transformer models' capacity for parallel processing, enabling faster and more efficient analysis of substantial datasets.
- Challenges in Capturing Relationships
Sequential processing often finds it challenging to effectively capture complex relationships between words, especially in longer stretches of text. The focus remains constrained to local dependencies, potentially missing crucial relationships that span wider regions of the input data. Transformer models address this by enabling the model to consider relationships between all elements simultaneously, thus improving overall accuracy in capturing intricate connections within the text.
- Impact on Model Capacity
Sequential processing models often face constraints in processing complex language structures. Their capacity to handle complex sentence structures or lengthy sentences with interconnected clauses is limited, which can lead to suboptimal results. Transformer models, however, can effectively handle these complexities due to their parallel processing and attention mechanisms.
In summary, sequential processing, while a fundamental approach, exhibits limitations in contextual understanding, computational efficiency, relationship capturing, and overall model capacity. Transformer models' departure from this approach, emphasizing parallel processing, results in significant improvements and has become essential for many advanced natural language processing tasks.
4. Multi-tasking Capabilities
Transformer models exhibit a notable capacity for multi-tasking. This capability stems from their architecture, which allows the model to simultaneously address multiple linguistic tasks within a single framework. This inherent multi-tasking functionality is a significant advantage, enabling a more comprehensive and effective approach to natural language processing. The model's ability to handle diverse tasks without requiring separate models for each task reduces computational overhead and enhances efficiency. This unified approach is particularly relevant for complex language processing scenarios where multiple tasks might be interwoven and interdependent.
Real-world applications highlight the practical significance of this multi-tasking capability. In a machine translation system, for instance, a single transformer model can not only translate text but also perform tasks like identifying named entities or detecting sentiment within the translated text. This integrated approach enhances the overall accuracy and effectiveness of the translation process. Similar integration can be seen in summarization systems, where the model can generate summaries while simultaneously identifying key entities or concepts within the input text. This unified approach enables more holistic and intelligent processing of information, crucial in fields ranging from language learning to content analysis.
The multi-tasking capabilities of transformer models represent a crucial advancement in natural language processing. This capability reduces the need for separate models for each task, streamlining the process and improving efficiency. The ability to perform multiple linguistic tasks simultaneously within a single model is a key factor in achieving more comprehensive and accurate results. While challenges remain in optimizing performance for highly specialized tasks, the potential for integrated solutions within a single framework suggests a path toward more robust and intelligent language processing systems.
5. Scalability & Efficiency
Transformer models exhibit a remarkable capacity for scalability and efficiency, factors critical to their widespread adoption and success. The architectural design of these models, particularly the use of parallel processing and attention mechanisms, allows for substantial increases in processing speed and the handling of substantial datasets. This enhanced efficiency is crucial for various applications, from machine translation to text summarization, enabling processing of larger volumes of text and data more rapidly.
The inherent parallel processing nature of transformer architectures allows the model to simultaneously process multiple parts of an input sequence. This contrasts with traditional recurrent models, which process elements sequentially, creating bottlenecks in processing speed, particularly with longer sequences. The ability to process multiple words concurrently substantially reduces the computational time required for complex tasks. This efficiency translates into faster training times for models and quicker responses in real-world applications. For instance, a transformer model can translate a lengthy document far more quickly than a model relying on sequential processing, allowing for more efficient handling of large-scale language processing tasks. The inherent scalability is also crucial, enabling the model to handle ever-increasing amounts of data without compromising performance. This adaptability is vital for evolving language datasets and ensures that models can maintain accuracy and speed as datasets grow. Furthermore, the efficiency of transformer models is crucial in real-time applications, such as live chatbots or language translation tools that require rapid responses to user input.
The combination of scalability and efficiency in transformer models is a key driver of their dominance in natural language processing. While other models may show promise in specific circumstances, the ability to process substantial amounts of data quickly, without compromising accuracy, makes transformer models exceptionally valuable for numerous applications. This capacity for scaling effectively with growing datasets remains a critical advantage, positioning these models for future advancements in language processing and other related AI applications. However, the complexity of these models can present challenges in terms of computational resources, and research continues to focus on optimizing their efficiency and further enhancing scalability, enabling greater accessibility and adaptability.
6. Deep Learning
Deep learning forms the bedrock of transformer models. These models leverage deep neural networks, a specific type of artificial neural network, to achieve their impressive performance in natural language processing tasks. The intricate architecture of transformer models hinges on deep learning principles for representing and processing information. Deep learning's role in transformer models is multifaceted, from the representation of input data to the prediction of output. Without the underpinnings of deep learning, the advanced contextual understanding, relationship capturing, and efficient parallel processing that distinguish transformer models would not be possible.
The connection between deep learning and transformer models is evident in the complex, multi-layered architectures of the latter. These layers, typically numerous, learn hierarchical representations of the input data. Each layer extracts progressively more abstract and nuanced features from the input text. For instance, early layers might identify basic grammatical structures, while deeper layers grasp the context and relationships between words and sentences. This hierarchical learning structure is a hallmark of deep learning models. The practical significance of this understanding lies in its application across diverse tasks: machine translation, text summarization, question answering, and text generation. The ability of deep learning to learn complex relationships from massive datasets is essential for the success of these tasks, and this deep understanding of language becomes apparent in the sophisticated outputs of transformer models.
In summary, deep learning is an indispensable component of transformer models. It provides the framework for learning intricate representations of language. Deep learning's ability to extract hierarchical features is critical for tasks involving complex contextual understanding. This understanding underpins the models' impressive performance, from accurate translations to sophisticated text generation. While deep learning is not the only factor contributing to the success of transformer models, its crucial role in constructing and enabling their capabilities is clear. Future advancements in transformer models will likely be intertwined with advancements in deep learning, potentially leading to even more sophisticated language processing systems.
Frequently Asked Questions
This section addresses common queries regarding transformer models, a significant advancement in natural language processing. Clear and concise answers are provided to clarify key concepts and dispel potential misunderstandings.
Question 1: What distinguishes transformer models from previous language models?
Transformer models differ significantly from earlier language models, primarily through their parallel processing architecture. Instead of processing words sequentially, like recurrent models, transformers analyze all words simultaneously, enabling them to capture complex relationships and context more effectively. This parallel processing allows for more efficient handling of longer sequences and greater contextual understanding. The introduction of attention mechanisms is another crucial distinction, allowing the model to focus on relevant parts of the input, enhancing accuracy in tasks like translation and summarization.
Question 2: How do attention mechanisms work in transformer models?
Attention mechanisms in transformers act as a "spotlight," directing the model's focus to the most relevant parts of the input sequence. These mechanisms assign weights to different parts of the input, giving higher importance to elements deemed crucial for understanding the overall context. This dynamic weighting ensures the model prioritizes critical information while downplaying less relevant details. This approach allows the model to understand intricate relationships between words, crucial for tasks needing comprehensive contextual comprehension, such as machine translation.
Question 3: What are some common applications of transformer models?
Transformer models find applications in diverse natural language processing tasks. Machine translation, text summarization, question answering, and text generation are prominent examples. Their ability to capture nuanced relationships between words allows for accurate and contextually aware results in these applications. In machine translation, for instance, the model goes beyond literal word-for-word conversions, focusing on the intended meaning and broader context.
Question 4: What are the advantages of using transformer models?
Transformer models offer several advantages over previous approaches. Superior performance in complex tasks like machine translation and text summarization is a key benefit. Their capacity to handle longer sequences of text and capture complex relationships is another strength. The parallel processing approach also leads to increased efficiency, enabling faster processing of large datasets. These factors have made transformer models dominant in many language-related applications.
Question 5: What are the limitations or challenges associated with transformer models?
Despite their strengths, transformer models have limitations. Computational resources required for training and running large models can be substantial. The complexity of these models can pose challenges in terms of interpretability, making it harder to understand why a model reaches a specific conclusion. Furthermore, although effective for various tasks, optimization for highly specific applications remains a continuing area of research. These challenges are actively being addressed by the research community.
These FAQs provide a starting point for understanding transformer models. Further exploration into specific applications or research areas may uncover more nuanced details.
Next, we will delve into the practical implementation of transformer models in specific applications.
Conclusion
Transformer models have revolutionized natural language processing, demonstrating significant advancements in understanding and processing language. Key features, such as parallel processing and attention mechanisms, have enabled these models to capture complex relationships between words, leading to superior performance in various tasks. This superior contextual understanding is crucial for applications like machine translation, text summarization, and question answering. The scalability and efficiency of transformer models further enhance their practicality, particularly with large datasets. Deep learning principles form the foundation for these models, enabling the intricate hierarchical representation of language. Despite certain limitations in computational resources and interpretability, the transformative impact of these models on language processing is undeniable. Their ongoing development and adaptation suggest a continued progression in the field of natural language processing.
The future trajectory of transformer models is promising, driven by ongoing research in optimizing efficiency, enhancing interpretability, and exploring new applications. Their ability to handle increasing data volumes, along with their capacity for increasingly sophisticated language understanding, positions them for continued dominance in the field. Further exploration of their capabilities and limitations will undoubtedly contribute to the advancement of natural language processing and potentially impact other artificial intelligence domains.

Detail Author:
- Name : Mrs. Kathryne Parisian
- Username : lauryn.hahn
- Email : davis.earlene@weber.biz
- Birthdate : 1991-09-20
- Address : 566 Era Trail New Jaidamouth, AL 23466
- Phone : 458.810.0082
- Company : Erdman, Durgan and Pollich
- Job : Legal Secretary
- Bio : Perspiciatis reiciendis dolorum natus natus sed a. Aut sapiente molestiae distinctio dolorem necessitatibus sint architecto. Recusandae neque qui unde nam ut nemo iusto.
Socials
facebook:
- url : https://facebook.com/jayne_schmidt
- username : jayne_schmidt
- bio : Animi consequatur impedit voluptatem porro.
- followers : 3839
- following : 2230
tiktok:
- url : https://tiktok.com/@jayne_schmidt
- username : jayne_schmidt
- bio : Dolorem dolores et blanditiis dignissimos qui officia magni.
- followers : 3102
- following : 1101
twitter:
- url : https://twitter.com/jayne_official
- username : jayne_official
- bio : Ea corporis vero qui earum perferendis. Qui officiis ut alias ut. Quos non maiores et. Temporibus qui libero expedita molestias praesentium est id.
- followers : 5933
- following : 2229
instagram:
- url : https://instagram.com/jayne_schmidt
- username : jayne_schmidt
- bio : Eveniet quam enim est culpa dolor. Illum qui autem pariatur unde.
- followers : 848
- following : 2159
